概念
散列表(哈希表)是一种无序符号表,将键作为数组的索引,而数组中键 i 处就是它对应的值,这样可以增大访问速度。散列算法分为两步:
- 用散列函数将键转化为一个索引
- 处理碰撞冲突(理想情况下,散列函数会将不同的键转化为不同的散列值,但在实际情况中,我们需要面对不同的键散列到相同索引的情况。)
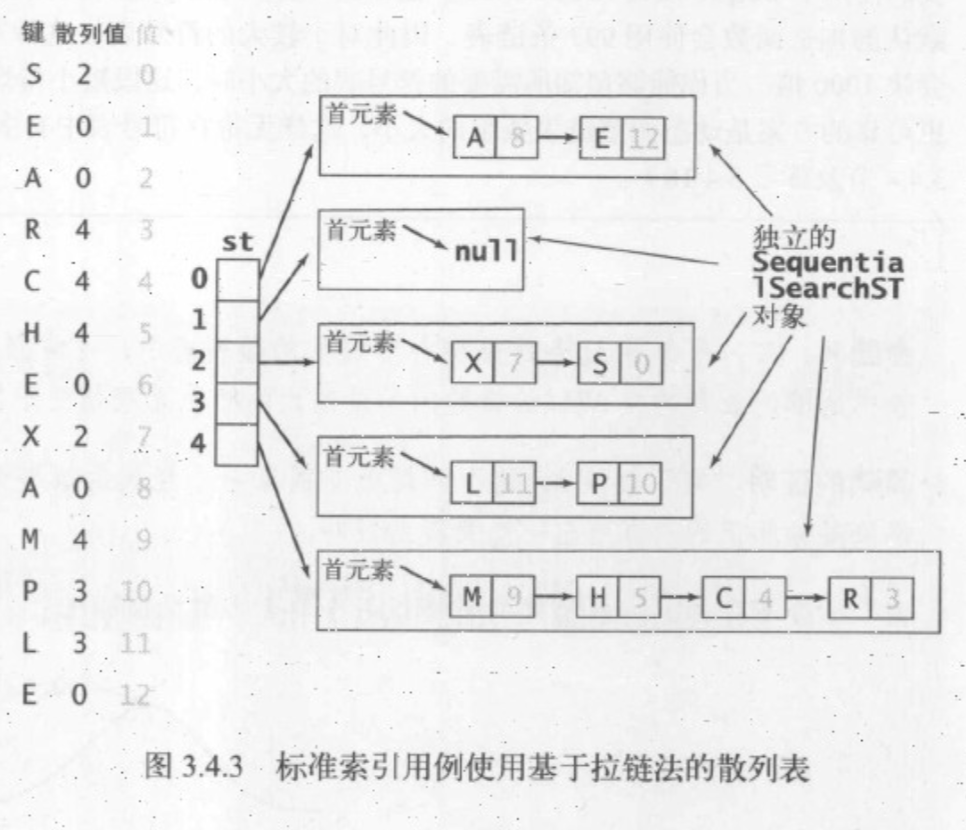
基于拉链法的散列表
拉链法的实现方式是将数组中的每个元素指向一条链表,链表中的每个节点储存了散列值为该索引的键的值。拉链法的查找分为两步,首先根据散列值找到相应的链表,再按顺序在链表中查找值。这样我们操作的其实是链表,降低了复杂度。
图解
代码实现
基于拉链法的散列表:
1 | public class SeparateChainingHashST<K extends Comparable<K>, V> { |